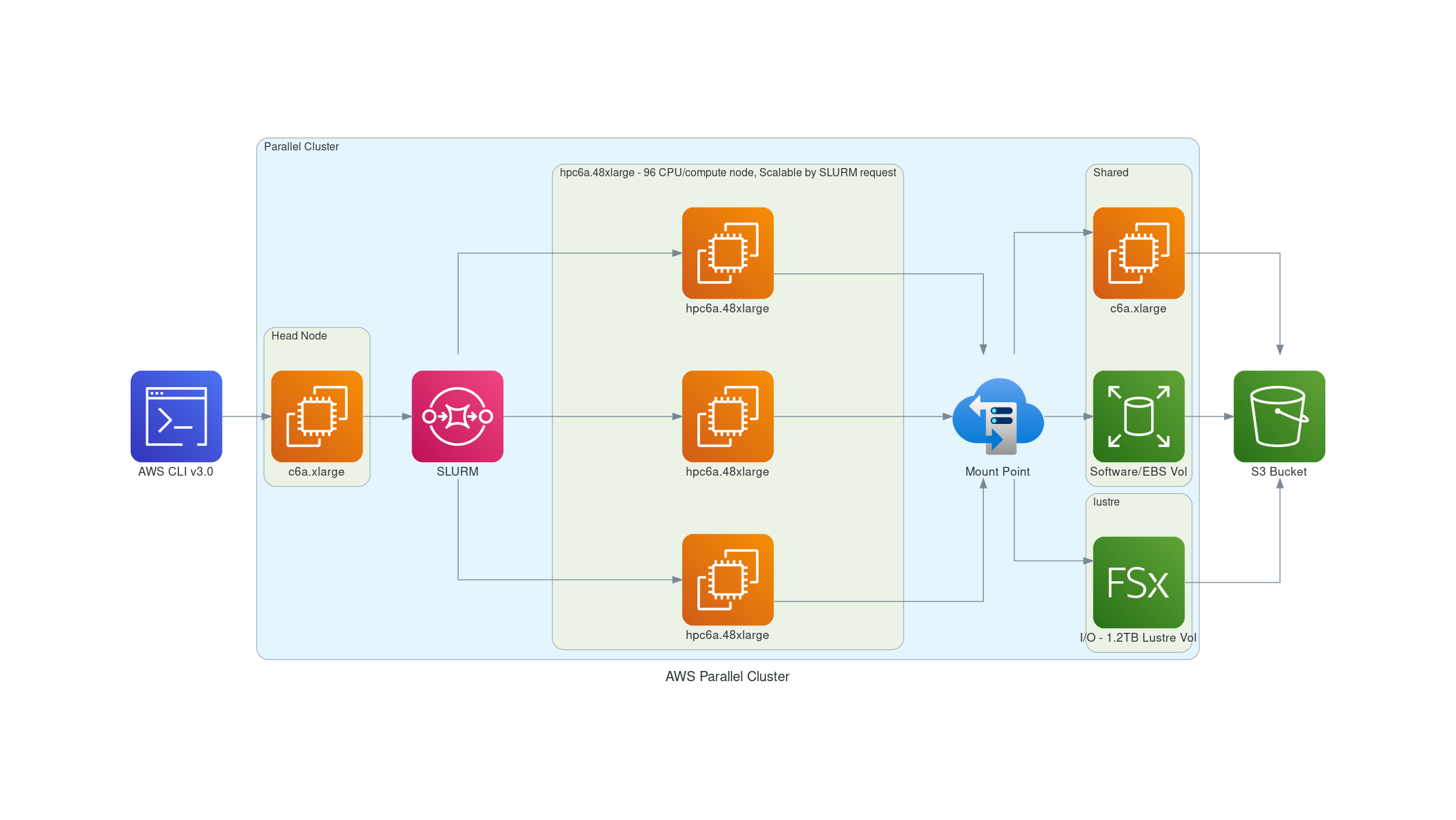
1.1. Configurations for running CMAQv5.3.3 on AWS ParallelCluster#
1.1.1. Recommend that users set up a spending alarm using AWS#
Configure alarm to receive an email alert if you exceed $100 per month (or what ever monthly spending limit you need).
See also
See the AWS Tutorial on setting up an alarm for AWS Free Tier. AWS Free Tier Budgets
1.2. Software Requirements for CMAQ on AWS ParallelCluster#
Tier 1: Native OS and associated system libraries, compilers
Operating System: Ubuntu2004
Tcsh shell
Git
Compilers (C, C++, and Fortran) - GNU compilers version ≥ 8.3
MPI (Message Passing Interface) - OpenMPI ≥ 4.0
Slurm Scheduler
Tier 2: additional libraries required for installing CMAQ
NetCDF (with C, C++, and Fortran support)
I/O API
R Software and packages
Tier 3: Software distributed thru the CMAS Center
CMAQv533
CMAQv533 Post Processors
Tier 4: R packages and Scripts
R QA Scripts
Software on Local Computer
AWS CLI v3.0 installed in a virtual environment
pcluster is the primary AWS ParallelCluster CLI command. You use pcluster to launch and manage HPC clusters in the AWS Cloud and to create and manage custom AMI images
run-instances is another AWS Command Line method to create a single virtual machine to run CMAQ described in chapter 6.
Edit YAML Configuration Files using vi, nedit or other editor (yaml does not accept tabs as spacing)
Git
Mac - XQuartz for X11 Display
Windows - MobaXterm - to connect to ParallelCluster IP address
1.2.1. AWS CLI v3.0 AWS Region Availability#
Note
The scripts in this tutorial use the us-east-1 region, but the scripts can be modified to use any of the supported regions listed in the url below. CLI v3 Supported Regions
1.2.2. CONUS 12US2 Domain Description#
GRIDDESC
'12US2'
'12CONUS' -2412000.0 -1620000.0 12000.0 12000.0 396 246 1
1.3. Single VM Configuration for CMAQv5.3.2_Benchmark_2Day_Input.tar.gz Benchmark#
c6a.2xlarge
1.4. ParallelCluster Configuration for 12US2 Benchmark Domain#
Note
It is recommended to use a head node that is in the same family a the compute node so that the compiler options and executable is optimized for that processor type.
Recommended configuration of the ParallelCluster HPC head node and compute nodes to run the CMAQ CONUS benchmark for two days:
Head node:
c5n.large
or
c6a.xlarge
(note that head node should match the processor family of the compute nodes)
Compute Node:
c5n.9xlarge (16 cpus/node with Multithreading disabled) with 96 GiB memory, 50 Gbps Network Bandwidth, 9,500 EBS Bandwidth (Mbps) and Elastic Fabric Adapter (EFA)
or
c5n.18xlarge (36 cpus/node with Multithreading disabled) with 192 GiB memory, 100 Gbps Network Bandwidth, 19,000 EBS Bandwidth (Mbps) and Elastic Fabric Adapter (EFA)
or
c6a.48xlarge (96 cpus/node with Multithreading disabled) with 384 GiB memory, 50 Gigabit Network Bandwidth, 40 EBS Bandwidth (Gbps), Elastic Fabric Adapter (EFA) and Nitro Hypervisor
or
hpc6a.48xlarge (96 cpus/node) only available in us-east-2 region with 384 GiB memory, using two 48-core 3rd generation AMD EPYC 7003 series processors built on 7nm process nodes for increased efficiency with a total of 96 cores (4 GiB of memory per core), Elatic Fabric Adapter (EFA) and Nitro Hypervisor (lower cost than c6a.48xlarge)
Note
CMAQ is developed using OpenMPI and can take advantage of increasing the number of CPUs and memory. ParallelCluster provides a ready-made auto scaling solution.
Note
Additional best practice of allowing the ParallelCluster to create a placement group. Network Performance Placement Groups
This is specified in the yaml file in the slurm queue’s network settings.
Networking:
PlacementGroup:
Enabled: true
Note
To provide the lowest latency and the highest packet-per-second network performance for your placement group, choose an instance type that supports enhanced networking. For more information, see Enhanced Networking. Enhanced Networking (ENA)
To measure the network performance, you can use iPerf to measure network bandwidth.
Note
Elastic Fabric Adapter(EFA) “EFA provides lower and more consistent latency and higher throughput than the TCP transport traditionally used in cloud-based HPC systems. It enhances the performance of inter-instance communication that is critical for scaling HPC and machine learning applications. It is optimized to work on the existing AWS network infrastructure and it can scale depending on application requirements.” “An EFA is an Elastic Network Adapter (ENA) with added capabilities. It provides all of the functionality of an ENA, with an additional OS-bypass functionality. OS-bypass is an access model that allows HPC and machine learning applications to communicate directly with the network interface hardware to provide low-latency, reliable transport functionality.” Elastic Fabric Adapter(EFA)
Note
Nitro Hypervisor “AWS Nitro System is composed of three main components: Nitro cards, the Nitro security chip, and the Nitro hypervisor. Nitro cards provide controllers for the VPC data plane (network access), Amazon Elastic Block Store (Amazon EBS) access, instance storage (local NVMe), as well as overall coordination for the host. By offloading these capabilities to the Nitro cards, this removes the need to use host processor resources to implement these functions, as well as offering security benefits. “ Bare metal performance with the Nitro Hypervisor
Importing data from S3 Bucket to Lustre
Justification for using the capability of importing data from an S3 bucket to the lustre file system over using elastic block storage file system and copying the data from the S3 bucket for the input and output data storage volume on the cluster.
Saves storage cost
Removes need to copy data from S3 bucket to Lustre file system. FSx for Lustre integrates natively with Amazon S3, making it easy for you to process HPC data sets stored in Amazon S3
Simplifies running HPC workloads on AWS
Amazon FSx for Lustre uses parallel data transfer techniques to transfer data to and from S3 at up to hundreds of GB/s.
Note
To find the default settings for Lustre see: Lustre Settings for ParallelCluster
Figure 1. AWS Recommended ParallelCluster Configuration (Number of compute nodes depends on setting for NPCOLxNPROW and #SBATCH –nodes=XX #SBATCH –ntasks-per-node=YY )