Configurations for running CMAQ on a Single VM or ParallelCluster#
Note
The tutorials presented here, require an AWS account, which requires a credit card. If you are diligent in terminating the resources created in this tutorial after you run the benchmark, the cost should be less than $15. Performance and Cost Optimization tables are provided in Chapter 5.
Sign up for an Amazon Web Services (AWS) Account#
From the Amazon Web Services website, http://aws.amazon.com, click on “Create an AWS account” on the upper right corner. After you have an account it will say “Sign into the Console”.
We highly recommend that users set up a spending alarm to help manage costs. You can configure alarm to receive an email alert if you exceed a specific dollar amount, e.g., $100 per month.
See also
See the AWS Tutorial on setting up an alarm for AWS Free Tier: AWS Free Tier Budgets
Software Requirements for CMAQ on AWS Single VM or ParallelCluster#
Tier 1: Native OS and associated system libraries, compilers
Operating System: Ubuntu2004
Tcsh shell
Git
Compilers (C, C++, and Fortran) - GNU compilers version ≥ 8.3
MPI (Message Passing Interface) - OpenMPI ≥ 4.0
Slurm Scheduler
Tier 2: additional libraries required for installing CMAQ
NetCDF (with C, C++, and Fortran support)
I/O API
Tier 3: Software developed by EPA and distributed through the CMAS Center
CMAQv5.4+
CMAQv5.4+ Post Processors
R code for QAing model ouput
Software on Local Computer
AWS ParallelCluster CLI v3.0 installed in a virtual environment
Text editors for editing scripts and configuration files (e.g., vi, nedit)
Git
Mac - XQuartz for X11 Display
Windows - MobaXterm - to connect to ParallelCluster IP address
Note
When working on the AWS Cloud you will need to select a Region for your workloads. (See AWS blog on What to consider when selecting a region). The scripts used in this tutorial use the us-east-1 region, but they can be modified to use any of the supported regions listed here: CLI v3 Supported Regions
Single VM Configuration for 12US1 Benchmark Domain#
c6a.48xlarge - (96 cpus/node with Multithreading disabled) with 384 GiB memory, 50 Gigabit Network Bandwidth, 40 EBS Bandwidth (Gbps), Elastic Fabric Adapter (EFA) and Nitro Hypervisor. (available in any region)
Name |
vCPUs |
cores |
Memory (GiB) |
Network Bandwidth (Gbps) |
EBS Throughput (Gbps) |
|---|---|---|---|---|---|
c6a.2xlarge |
8 |
4 |
16 |
Up to 12.5 |
Up to 6.6 |
c6a.8xlarge |
32 |
16 |
64 |
12.5 |
6.6 |
c6a.48xlarge |
192 |
96 |
384 |
50 |
40 |
or
hpc6a.48xlarge (96 cpus/node) with 384 GiB memory, using two 48-core 3rd generation AMD EPYC 7003 series processors built on 7nm process nodes for increased efficiency with a total of 96 cores (4 GiB of memory per core), Elastic Fabric Adapter (EFA) and Nitro Hypervisor (lower cost than c6a.48xlarge) only available in us-east-2 region
Name |
cores |
Memory (GiB) |
EFA Network Bandwidth (Gbps) |
Network Bandwidth(Gbps) |
|---|---|---|---|---|
Hpc6a.48xlarge |
96 |
384 |
100 |
25 |
ParallelCluster Configuration for 12US1 Benchmark Domain#
Note
It is recommended to use a head node that is in the same family a the compute node so that the compiler options and executable is optimized for that processor type.
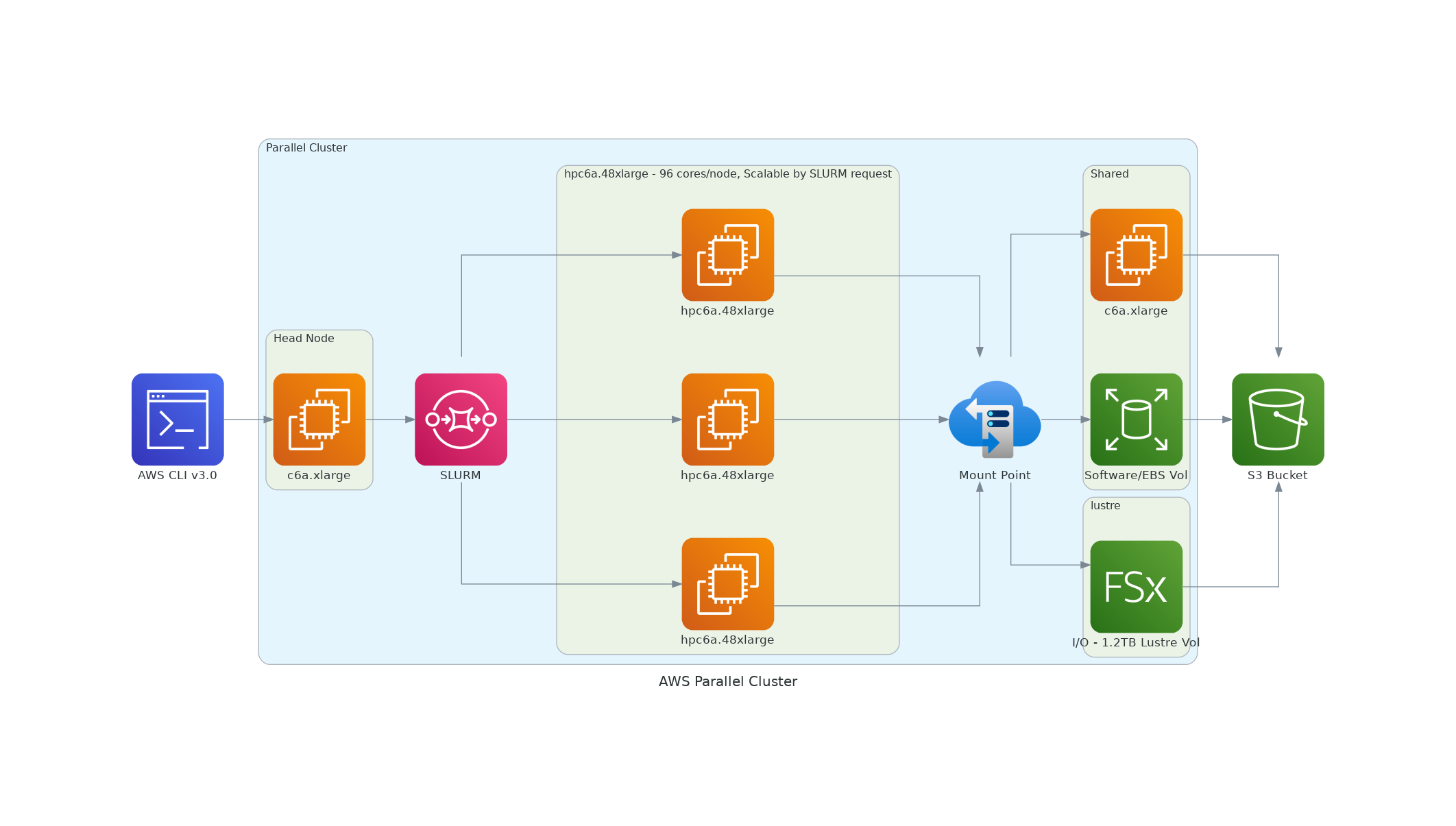
There are two recommended configuration of the ParallelCluster HPC head node and compute nodes to run the CMAQ CONUS benchmark for two days:
First configuration:
Head node:
c6a.xlarge
(note that head node should match the processor family of the compute nodes)
Compute Node:
hpc6a.48xlarge (96 cpus/node) with 384 GiB memory, using two 48-core 3rd generation AMD EPYC 7003 series processors built on 7nm process nodes for increased efficiency with a total of 96 cores (4 GiB of memory per core), Elastic Fabric Adapter (EFA) and Nitro Hypervisor (lower cost than c6a.48xlarge) only available in us-east-2 region
or (more costly option, but available in all regions)
c6a.48xlarge (96 cpus/node with Multithreading disabled) with 384 GiB memory, 50 Gigabit Network Bandwidth, 40 EBS Bandwidth (Gbps), Elastic Fabric Adapter (EFA) and Nitro Hypervisor
Note
CMAQ is developed using OpenMPI and can take advantage of increasing the number of CPUs and memory. ParallelCluster provides a ready-made auto scaling solution.
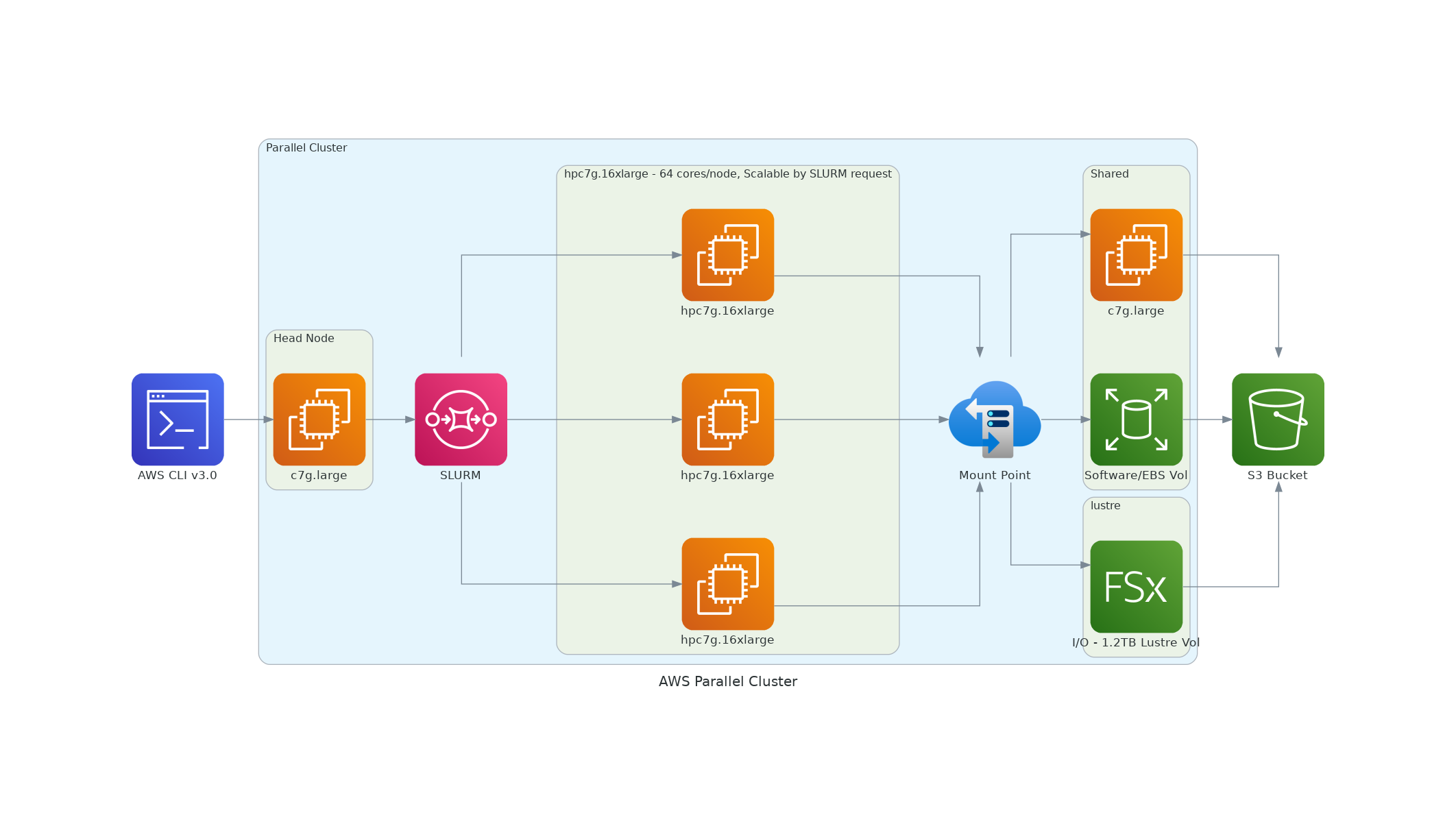
Figure 1. AWS Recommended ParallelCluster Configuration (Number of compute nodes depends on setting for NPCOLxNPROW and #SBATCH –nodes=XX #SBATCH –ntasks-per-node=YY )
Second configuration (Least expensive - see chapter on Cost and Performance Optimization):
Head node:
c7g.large
(note that head node should match the processor family of the compute nodes)
Compute Node:
hpc7g.16xlarge (64 cores/node) with 128 GiB memory (2 GiB of memory per core), Arm-based custom Graviton3E processors, which provide Double Data Rate 5 (DDR5) memory that offers 50% more bandwidth compared to DDR4, Elastic Fabric Adapter (EFA) and Nitro Hypervisor only available in us-east-1 region